Why Isn't ChatGPT Citing Your Website? I Tested 5 Axes on a DR 25 Site and Got 1,500 Citations
1,500 AI citations on a DR 25 site in 90 days. The 5 checks (schema, llms.txt, OpenGraph, semantic HTML, robots.txt) that decide whether ChatGPT cites you.
Why this matters
Bing Webmaster Tools shows 1,500 AI citations for my DR 25 site over 90 days, with zero backlinks added in the window. The conventional wisdom says sites with 32,000+ referring domains are 3.5x more likely to get cited. What moved my citations instead: five checks (schema markup, llms.txt, OpenGraph, semantic HTML, and AI-bot access in robots.txt), changed together. I can't isolate which one carried the weight, but citation eligibility, not domain authority, is the lever a small site can actually pull.
Five checks determine whether AI assistants can parse, trust, and cite your pages: schema markup, llms.txt, OpenGraph metadata, semantic HTML, and AI-bot access in robots.txt. My DR 25 site got 1,500 citations in 90 days after fixing all five. Most small-business sites fail at least three of these checks, and some fixes take under 30 minutes.
1,500. That’s how many AI citations Bing Webmaster Tools shows for a DR 25 site I own, over the last 90 days. A citation is when an AI assistant uses your page as a source in its answer. If you’re a founder or marketing lead who keeps hearing “AI visibility” and isn’t sure what to do about it, this number is the case for taking it seriously. The single biggest question pulling my site into answers: “site authority impact AI citation rankings,” at 139 citations on its own.
The conventional read says that shouldn’t happen. Sites with 32,000+ referring domains are reported to be 3.5x more likely to get cited by AI assistants (seo.com, GEO Trends 2026). I had a fraction of that. So either I got lucky, or domain authority isn’t the whole mechanism.
I’m Chudi Nnorukam. I build agent tooling for solo operators and I run citability.dev, where I audit why AI assistants like ChatGPT, Perplexity, and Claude do or don’t surface a given site. This post is the short version of what I learned getting a low-authority site cited.
What didn’t I know when I started?
I didn’t know what made a page citable, whether AI assistants even crawled my site, or how to measure any of it. The measurement gap was the expensive one. You can’t improve a citation rate you can’t see. (If you want the full measurement methodology, I published it as a freeCodeCamp guide: How to Measure Your AI Citation Rate Across ChatGPT, Perplexity, and Claude.)
Most small-business sites are in this exact position right now: 37% of product discovery queries already start in AI interfaces like ChatGPT and Perplexity (HubSpot AEO guide), publishers report up to 40% traffic loss from AI Overviews (seo.com), and the average founder has zero instrumentation on any of it.
The question most founders are actually asking underneath “how’s my SEO?” is quieter than that. It’s “is my site about to become invisible?” Nobody says that part out loud.
Three things I got wrong
First: I treated it like keyword SEO. I optimized pages for search phrases and waited. Generative engines don’t rank keywords the way Google’s ten blue links did. They parse topics, extract claims, and decide whether your page is the cleanest source for a specific answer. Keyword density did nothing. Extractable, self-contained answers did.
Second: I assumed crawler access was a given. It wasn’t. My robots.txt wasn’t explicitly allowing ChatGPT-User, PerplexityBot, or ClaudeBot. The fix took under 30 minutes. The fact that I’d skipped it for months is the kind of thing an audit catches and intuition doesn’t.
Third: I wrote clever copy. Evocative hero lines, metaphors, the stuff that wins design awards. This is really a parseability failure, the same one as hiding content behind JavaScript. AI assistants cite what they can parse, resolve, and trust, and a model reading a vague hero section can’t tell who you are, what you do, or for whom. Vague copy isn’t just weak marketing anymore. It’s unparseable, and unparseable means uncited.
What actually moved citations?
Citation eligibility, in my testing, comes down to five axes, and most small-business sites fail at least three of them:
 The five checks that seemed to decide, on my site, whether an AI assistant could parse, trust, and cite a page. Each feeds the same outcome.
The five checks that seemed to decide, on my site, whether an AI assistant could parse, trust, and cite a page. Each feeds the same outcome.
- Schema markup. Structured data that labels what each page is (an article, a product, an FAQ) so machines don’t have to guess. FAQPage schema in particular, because AI models prioritize question-and-answer formats they can lift directly.
- llms.txt. A plain-text file on your site that gives language models a map of your most important pages, the way robots.txt talks to search crawlers. In 2026 this moved from experiment to recognized signal: Anthropic, Stripe, Vercel, and Cloudflare all publish one (implementation guide). It takes a few hours and does no harm where it’s not yet consumed.
- OpenGraph metadata. How your pages resolve when models and aggregators unfurl them.
- Semantic HTML. Headings that mean something, content in the markup instead of behind JavaScript. (This axis keeps extending: agent-facing standards like WebMCP build on the same parseability foundation. I wrote A Developer’s Guide to WebMCP on freeCodeCamp if you want the agent-interop layer.)
- AI-bot robots.txt. Explicitly allowing the crawlers you want: GPTBot, OAI-SearchBot, PerplexityBot, ClaudeBot, Google-Extended.
I instrumented all five on my own site, fixed what failed, and tracked citations weekly. To be precise about what I can and can’t claim: citations grew alongside those changes, and I added zero referring domains in the window, so link building wasn’t the driver. But I changed the axes together, so I can’t tell you which one mattered most.
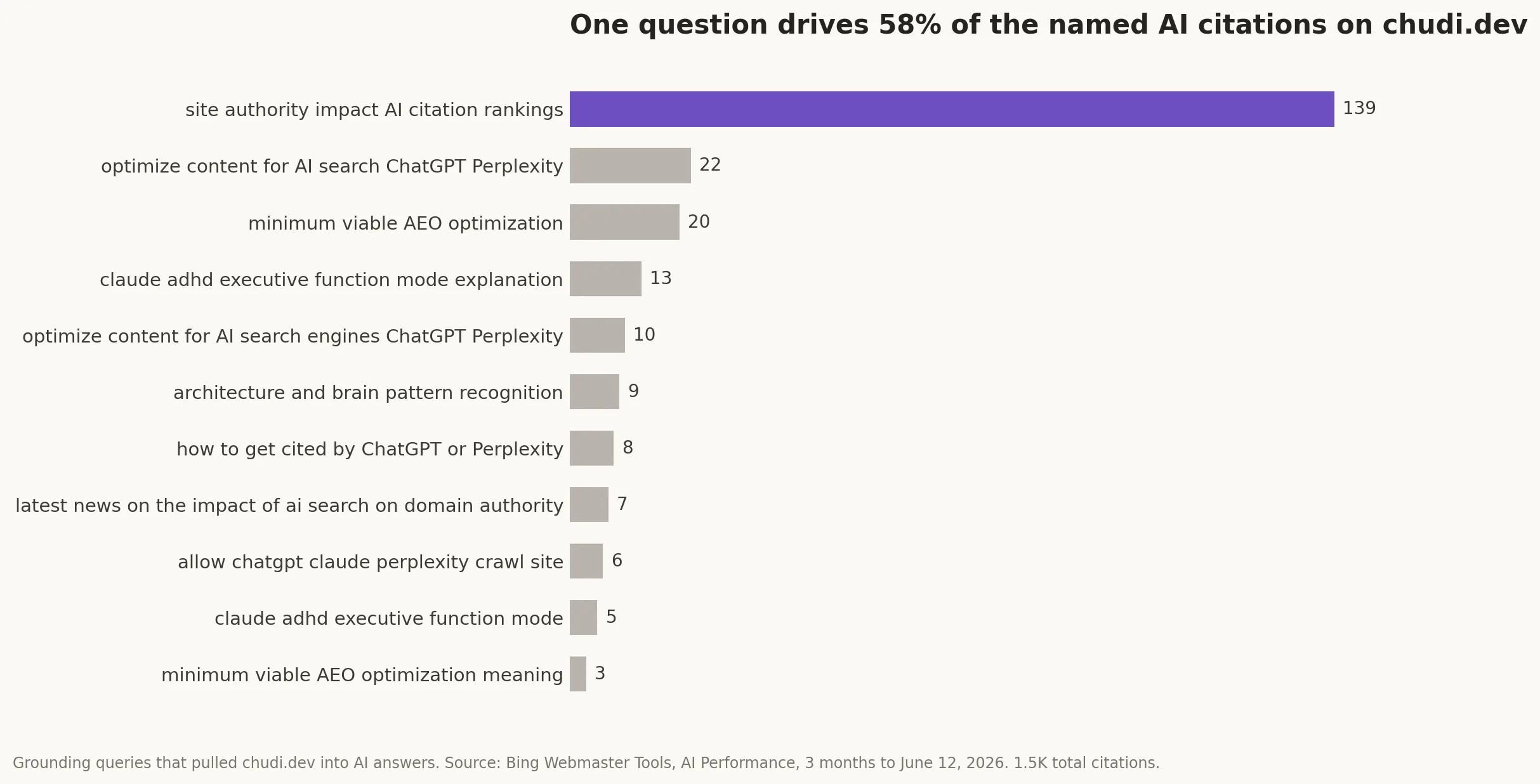 The questions (Bing calls them “grounding queries”) that pulled chudi.dev into AI answers. Source: Bing Webmaster Tools, 3 months to June 12, 2026. The earlier chapter of this number, when it was 1,200 and I’d just discovered the dashboard, is in I Found 1,200 AI Citations Hiding in Bing Webmaster Tools.
The questions (Bing calls them “grounding queries”) that pulled chudi.dev into AI answers. Source: Bing Webmaster Tools, 3 months to June 12, 2026. The earlier chapter of this number, when it was 1,200 and I’d just discovered the dashboard, is in I Found 1,200 AI Citations Hiding in Bing Webmaster Tools.
The audit I used runs as a self-serve check: 15 checks across SEO Foundation and AI Infrastructure, scored per section, with a verdict at the end. Developers can run it from a terminal with one curl call.
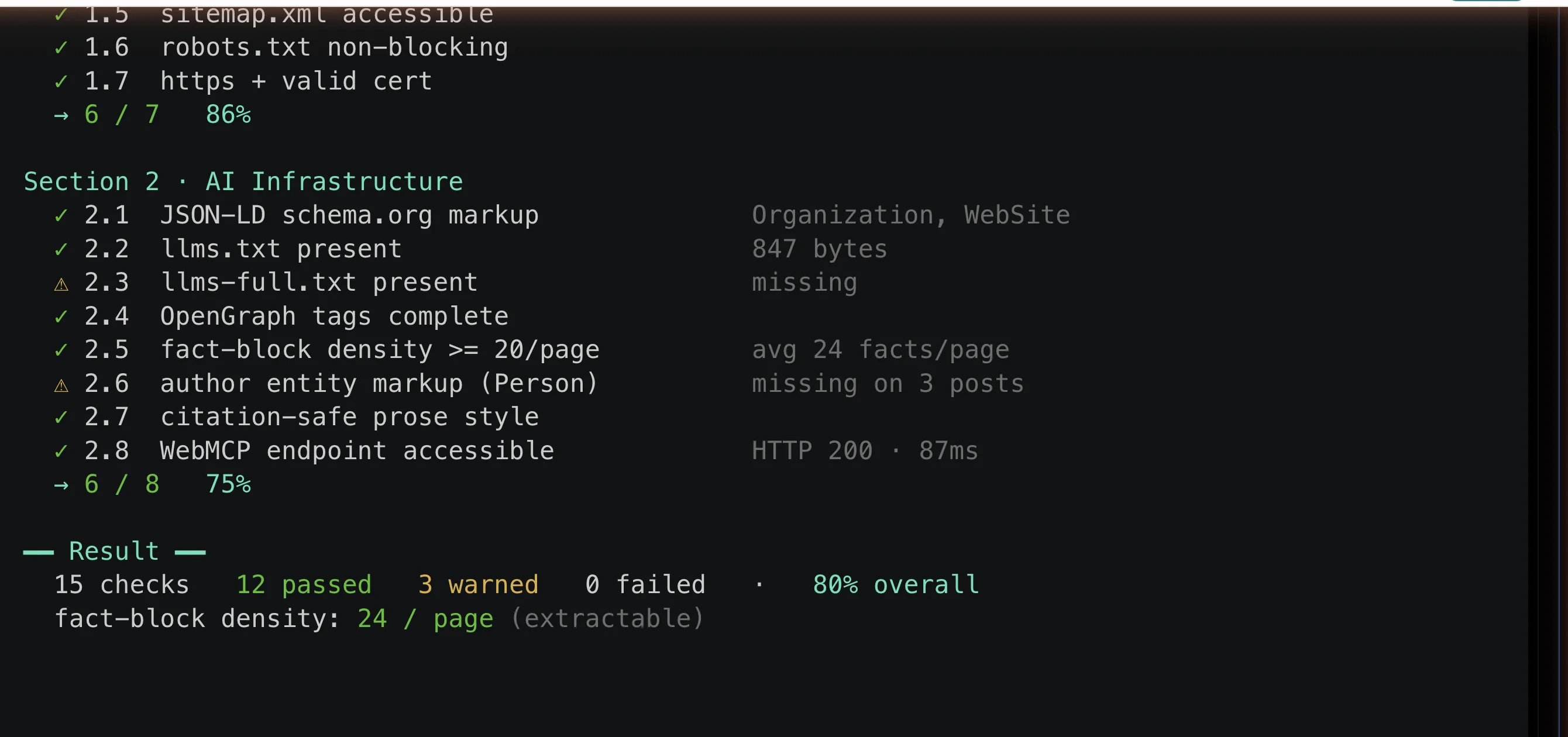 A live run against my own site. Even the site with 1,500 citations carries 3 warnings.
A live run against my own site. Even the site with 1,500 citations carries 3 warnings.
The other pattern in my data: long-tail questions are where low-authority sites win. Queries of 7+ words are where AI Overviews trigger most and where the big-domain advantage thins out (Averi, the 7-word rule). “Why isn’t ChatGPT citing my website” is winnable for a small site. “AI marketing” is not. Long-tail in 2026 is a citation bet, not a traffic bet.
If you want the 30-minute version of this for your own site: check your robots.txt for the three bots above, add an llms.txt, and rewrite your homepage first line so a model could quote it and a stranger would know what you do. That’s the floor.
What I still can’t prove
My data comes from one site, one niche, 90 days. I can’t rule out that Copilot weights my niche unusually, or that the citation rate decays once more competitors instrument the same axes. I don’t have a clean answer for how much each axis contributes individually; I changed them inside the same window, which is a confound I’d fix if I ran it again.
I also don’t know how durable llms.txt adoption is. The skeptic case is real: some platforms read it, some ignore it, and the standard could stall. My read is it’s a cheap hedge either way, but that’s a bet, not a finding.
The part I’m testing next: whether LinkedIn posts now outperform owned blogs as a citation source. LinkedIn has reportedly jumped from the #11 to the #5 most-cited domain on ChatGPT in three months, and published posts overtook profile pages. If that holds, the playbook for small founders changes again.
What I’d want you to take from this isn’t my number. It’s that citation eligibility is checkable, on your site, today, and most of the fixes are measured in minutes, not months. Whether my 1,500 generalizes to your niche is exactly the kind of thing I can’t promise from one site’s data.
90 days, 5 axes, 1,500 citations, DR 25. That’s the data I have, pulled from Bing Webmaster Tools on June 12, 2026.
Want to know which of the 5 axes your site fails? citability.dev runs a free scan in about 3 minutes. Instant results on the page.
· Frequently asked
FAQ
Why isn't ChatGPT citing my website?
The most common reasons: your robots.txt blocks or doesn't allow AI crawlers (GPTBot, PerplexityBot, ClaudeBot), your content isn't extractable as self-contained answers, or your pages lack the structure (schema, semantic HTML) models use to parse and attribute. Domain authority matters less than citation eligibility for long-tail questions.
What is an AI citation?
When an AI assistant (ChatGPT, Perplexity, Claude, Copilot) uses your page as a source in its answer and links or names it. Bing Webmaster Tools reports these in its AI Performance tab.
What's the fastest fix to get AI assistants citing your site?
Under 30 minutes: explicitly allow ChatGPT-User, PerplexityBot, and ClaudeBot in robots.txt, then rewrite your homepage first line so a stranger (or a model) knows who you are, what you do, and for whom.
Does llms.txt actually work?
Mixed evidence. Some platforms read it, some ignore it. It costs a few hours and does no harm, so my read is it's a cheap hedge. That's a bet, not a finding.
· Sources & further reading
Sources & Further Reading
Further reading
- I Spent $10K on AEO and Got Zero AI Citations. Here Is the Audit Section That Would Have Caught Why. /blog/citability-section-5-off-site-authority-launch citability.dev now scores Wikipedia, Wikidata, and JSON-LD sameAs presence. Free, opt-in, under 10s. Part of the AVR Framework, see chudi.dev/framework.
- I Audited 7 Websites for AI Citability. Here Is What Actually Predicts Citations. /blog/ai-citability-audit-what-predicts-citations Ahrefs has DA 92 and gets cited by AI 5% of the time. If you don't know whether your site is ready to be cited, you're guessing. I audited 7 websites to find what actually predicts AI citations, so you can audit your own website content for AI citation readiness before spending another dollar on backlinks.
- Schema.org for Answer Engines, the 40 Properties That Matter /blog/schema-org-answer-engines-guide A tactical guide to the Schema.org properties answer engines actually read. Which fields move citation decisions, which are noise, and how sub-DR-20 operators compress a full JSON-LD graph into the forty that matter.
- Entity Optimization for Brands in AI Search /blog/entity-optimization-brands-ai-search Rank is a single-page game. Entity coherence is the compounding game. How sub-DR-20 brands engineer a Person + Organization graph that AI search engines actually cite.
- I Found 1,200 AI Citations Hiding in Bing Webmaster Tools /blog/find-ai-citations-bing-webmaster-tools A freeCodeCamp guest post and one overlooked Bing dashboard surfaced ~1,200 Microsoft Copilot citations to my DR-25 site. Here is how to read your own.
What do you think?
I post about this stuff on LinkedIn every day and the conversations there are great. If this post sparked a thought, I'd love to hear it.
Discuss on LinkedIn