Entity Optimization for Brands in AI Search
Rank is a single-page game. Entity coherence is the compounding game. How sub-DR-20 brands engineer a Person + Organization graph that AI search engines actually cite.
Why this matters
AI engines do not cite pages. They cite entities. Optimizing for a coherent Person + Organization graph, consistent sameAs links, and a specific knowsAbout surface moves a sub-DR-20 site from invisible to quoted faster than any on-page SEO sprint.
In this cluster
Cluster context
This article sits inside AI Visibility Engineering.
Entity graphs, schema architecture, and citation mechanics for sub-DR-20 sites competing on AI citations, not SERP rank.
SEO optimizes for rank. Answer engines optimize for citation-worthiness. This cluster is the engineering playbook for the second game, sized for operators, not enterprise SEO teams.
Why ChatGPT Isn't Citing Your Site: 6 AEO Factors
ChatGPT and Perplexity skip most sites for six measurable reasons. The 6 AEO factors that decide which sources get cited, and how to fix each one.
Schema.org for Answer Engines, the 40 Properties That Matter
A tactical guide to the Schema.org properties answer engines actually read. Which fields move citation decisions, which are noise, and how sub-DR-20 operators compress a full JSON-LD graph into the forty that matter.
Perplexity vs ChatGPT: Different Citation Rules
Perplexity quotes liberally. ChatGPT quotes selectively. The engine-level differences in citation behavior that change what a sub-DR-20 brand should optimize for, engine by engine.
AI search engines do not rank pages. They score entities, then quote the entity that best matches the query. For a sub-DR-20 brand, this is the good news. You cannot outspend enterprise SEO teams on backlinks. You can out-engineer them on entity coherence. The broader AEO framework this entity-optimization fits inside is Answer Engine Optimization Explained.
This post is the engineering playbook for that work. It covers the three schemas that anchor the graph, the sameAs surface where most brands leak trust, the knowsAbout field that tells engines what you are an authority on, and the measurement loop that tells you when it is working. The reference model throughout is chudi.dev (the Person brand) and citability.dev (the product brand): a deliberate two-node graph that synergizes without cannibalizing.
§1, Why AI citations resolve to entities, not URLs
Classical SEO optimized for pages. Answer engines optimize for the entity behind the page. If two sites say the same thing and one site has a coherent Person + Organization + sameAs graph, the engine quotes the coherent site even when the other page ranks higher in traditional SERPs. Cite the entity, not the URL. That is the mental model shift this cluster pivots on.
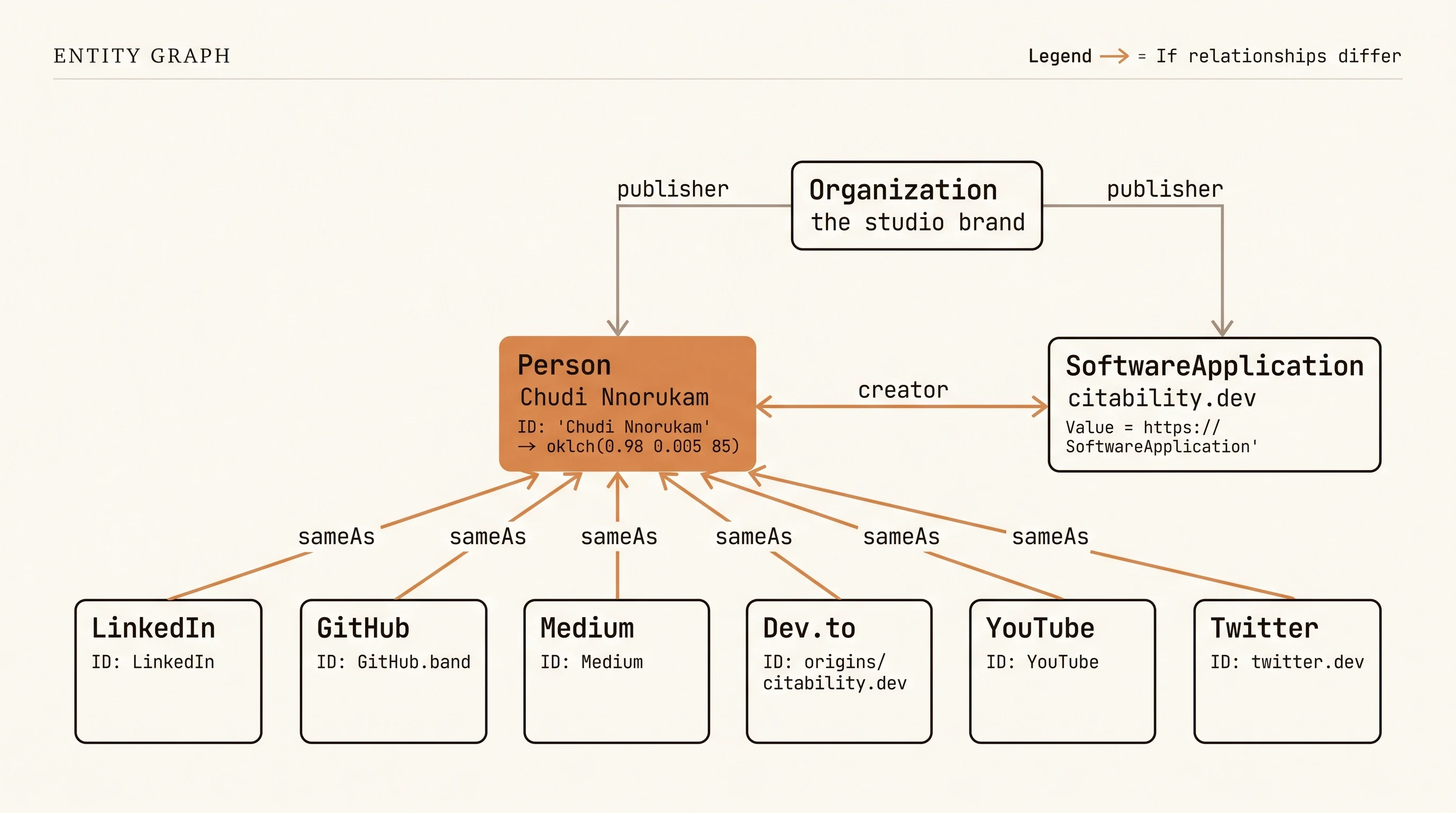
§2, The three anchor schemas
Every resilient entity graph has three anchor schemas. Person. Organization. SoftwareApplication. They cross-reference through creator, publisher, and about fields. Miss one anchor and the graph reads as a disconnected individual, a disconnected company, or a disconnected tool. Engines pick the version of your story they find easiest to summarize, which may not be the version you want quoted.
§3, sameAs coherence across platforms
The sameAs array is the single most valuable field in the Person schema for sub-DR-20 brands. It is also the field most brands let drift. Six platforms. Six subtly different job titles. Six subtly different descriptions. Engines treat this as ambiguity and choose a canonical, usually the platform with the highest authority, not the one you care about.
§4, The knowsAbout surface nobody uses
knowsAbout is the declarative authority claim. Use it to stake your territory. For chudi.dev, the stake is AI Visibility Engineering, Generative Engine Optimization, Entity Graph Architecture, and Sub-DR-20 SEO. Four claims. Four phrases an engine can match against a query.
§5, The citation flow
When a query arrives, an AI engine runs a pipeline. Retrieve candidate entities. Score coherence. Gate. Cite. Optimizing for citation means shortening the distance between query and gate.
§6, Measurement: how you know it is working
The answer engines that matter (Perplexity, ChatGPT with search, Google AI Overviews) do not expose rank. They expose citations. Measurement is a different instrument than Google Search Console. Track citation count per engine, quote length per citation, and coherence-check failures across your sameAs graph. Before tracking what engines cite, confirm your entity signals are complete with the AEO audit tool.
Bridge, from thinking to measurement
This post describes the thinking. citability.dev is the instrumentation. Run the citability scorer on any chudi.dev post to see what the engine actually extracts, which entity it resolves to, and where the coherence gates are failing.
· Frequently asked
FAQ
Why do AI search engines cite entities instead of pages?
AI search engines score entities, then quote the one that best matches a query. If two sites say the same thing and one has a coherent Person plus Organization plus sameAs graph, the engine quotes the coherent site even when the other page ranks higher in traditional search results. The entity is the unit of trust, not the URL.
What are the three anchor schemas that build a resilient entity graph?
Person, Organization, and SoftwareApplication. They must cross-reference each other through creator, publisher, and about fields. Missing one anchor makes the graph read as disconnected, and engines may pick the version of your story they find easiest to summarize, which may not be the version you want quoted.
What is the knowsAbout field and why does it matter for AI citations?
knowsAbout is Schema.org's declarative authority claim inside the Person type. It lists the topics you are an authority on, giving engines explicit phrases to match against queries. The post cites four example claims: AI Visibility Engineering, Generative Engine Optimization, Entity Graph Architecture, and Sub-DR-20 SEO. It is the most under-used field in the Person schema.
· Sources & further reading
Sources & Further Reading
Further reading
- Schema.org for Answer Engines, the 40 Properties That Matter /blog/schema-org-answer-engines-guide A tactical guide to the Schema.org properties answer engines actually read. Which fields move citation decisions, which are noise, and how sub-DR-20 operators compress a full JSON-LD graph into the forty that matter.
- Originality Signals and Citation Patterns /blog/originality-signals-ai-citation-patterns AI engines deprioritize pages that look like everything else. The originality signals that move a post from the summary layer into the quote layer, and why recap content is the new thin content.
- Perplexity vs ChatGPT: Different Citation Rules /blog/perplexity-vs-chatgpt-citation-rules Perplexity quotes liberally. ChatGPT quotes selectively. The engine-level differences in citation behavior that change what a sub-DR-20 brand should optimize for, engine by engine.
- The 90-Day AI Visibility Roadmap I Run for Sub-DR-20 Sites /blog/building-ai-visibility-roadmap The 90-day AI visibility roadmap I run for sub-DR-20 sites: entity-graph baseline, five canonical pages, co-mention seeding, and a citation dashboard.
- I Spent $10K on AEO and Got Zero AI Citations. Here Is the Audit Section That Would Have Caught Why. /blog/citability-section-5-off-site-authority-launch citability.dev now scores Wikipedia, Wikidata, and JSON-LD sameAs presence. Free, opt-in, under 10s. Part of the AVR Framework, see chudi.dev/framework.
Reading Path
Continue the AI Visibility Engineering track
Contextual next reads
Why ChatGPT Isn't Citing Your Site: 6 AEO Factors
ChatGPT and Perplexity skip most sites for six measurable reasons. The 6 AEO factors that decide which sources get cited, and how to fix each one.
Schema.org for Answer Engines, the 40 Properties That Matter
A tactical guide to the Schema.org properties answer engines actually read. Which fields move citation decisions, which are noise, and how sub-DR-20 operators compress a full JSON-LD graph into the forty that matter.
Perplexity vs ChatGPT: Different Citation Rules
Perplexity quotes liberally. ChatGPT quotes selectively. The engine-level differences in citation behavior that change what a sub-DR-20 brand should optimize for, engine by engine.
What do you think?
I post about this stuff on LinkedIn every day and the conversations there are great. If this post sparked a thought, I'd love to hear it.
Discuss on LinkedIn